
AI sentiment monitoring is the discipline of measuring how large language models describe your brand in generative search responses. Because LLMs influence buyer research and vendor shortlists, even subtle tonal shifts can affect trust and recommendation frequency. This guide explains why sentiment impacts AI visibility, how to measure it manually and automatically, how to compare across models, how to detect sentiment drift early, and how to build structured correction cycles inside your AIO framework.
AI Sentiment Monitoring
When someone asks an AI assistant, “Is this company reliable?” the answer is not a link list. It is a synthesized narrative. That narrative becomes perception.
AI sentiment monitoring focuses on analyzing the tone, positioning, and contextual signals used by large language models when referencing your brand. Instead of tracking where you rank, you track how you are framed.
In traditional SEO, page position was the KPI.
 In generative search, language is the KPI.
In generative search, language is the KPI.
If an LLM describes your company as:
- “well-regarded and widely adopted,”
- “growing but relatively new,” or
- “subject to mixed reviews,”
Each variation affects buyer psychology differently.
This is where structured AI brand perception tracking becomes essential to long-term visibility under an AIO (Artificial Intelligence Optimization) strategy.
AI models learn associations. The stronger the positive association clusters around your brand, the more confidently it appears in recommendation contexts.
Why sentiment affects AI recommendations

LLMs operate on probabilistic prediction. They do not “decide” who is best; they generate outputs based on patterns in training data and real-time signals.
Sentiment influences three critical layers:
1. Inclusion Probability
Brands consistently framed with authoritative language are more likely to appear in recommendation lists.
2. Confidence Language
Phrases like “widely trusted,” “industry-recognized,” or “market leader” create higher persuasion impact than neutral wording such as “offers services in.”
3. Comparative Positioning
In prompts like “Compare Company A and Company B,” tone determines perceived advantage.
Research across enterprise buying behavior indicates that AI-assisted research increasingly shapes early-stage shortlisting. If AI outputs subtly downplay your authority, conversion friction increases.
In other words:
Tone modifies trust.
Trust modifies recommendations.
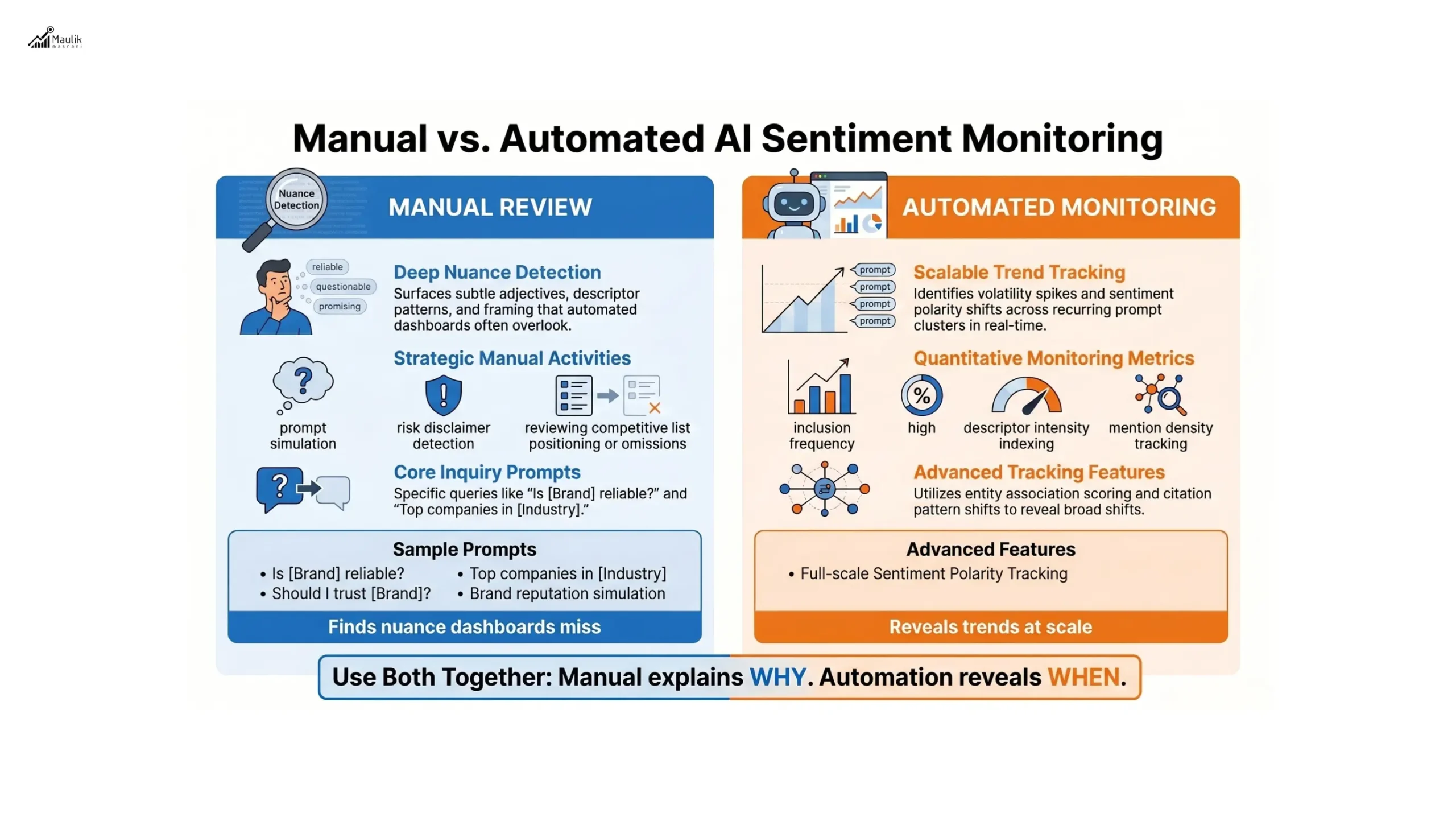
Manual vs automated AI checks
Effective monitoring combines qualitative review and scalable measurement.
Manual AI Sentiment Reviews
Manual audits focus on prompt simulation. You test structured queries such as:
- “Is [Brand] reliable?”
- “What are the strengths and weaknesses of [Brand]?”
- “Top companies in [Industry].”
- “Should I trust [Brand]?”
During manual reviews, analyze:
- Adjectives and descriptors
- Risk disclaimers
- Presence in competitive lists
- Omission patterns
- Summary framing
Manual testing surfaces nuance that dashboards often miss.
For example, a model may describe your brand positively but consistently place competitors first. That ordering matters.
Automated AI Sentiment Monitoring
As brand scale increases, automation becomes critical.
Automated systems typically:
- Run recurring prompt clusters
- Classify sentiment polarity
- Measure inclusion frequency
- Track descriptor intensity
- Identify volatility spikes
More advanced setups integrate:
- Entity association scoring
- Citation pattern shifts
- Mention density tracking
- Descriptor strength indexing
 For example:
For example:
| Metric | Month 1 | Month 2 | Month 3 |
| Positive Framing % | 78% | 70% | 61% |
| Competitive Inclusion Rate | 85% | 82% | 74% |
| Authority Descriptor Density | High | Medium | Medium-Low |
This type of trendline analysis enables proactive AIO intervention before perception declines materially.
Manual analysis explains why.
Automation reveals when.
Cross-model testing
Not all LLMs behave identically.
Different models:
- Access different web layers
- Weigh citations differently
- Refresh knowledge at varying intervals
- Prioritize structured signals differently
Cross-model testing answers key questions:
- Is sentiment consistent across platforms?
- Does one model use weaker authority descriptors?
- Are competitors framed more strongly elsewhere?
- Are you omitted in one ecosystem but included in another?
For example:
Model A response:
“Brand X is a recognized enterprise provider with strong compliance credentials.”
Model B response:
“Brand X offers services in enterprise compliance solutions.”
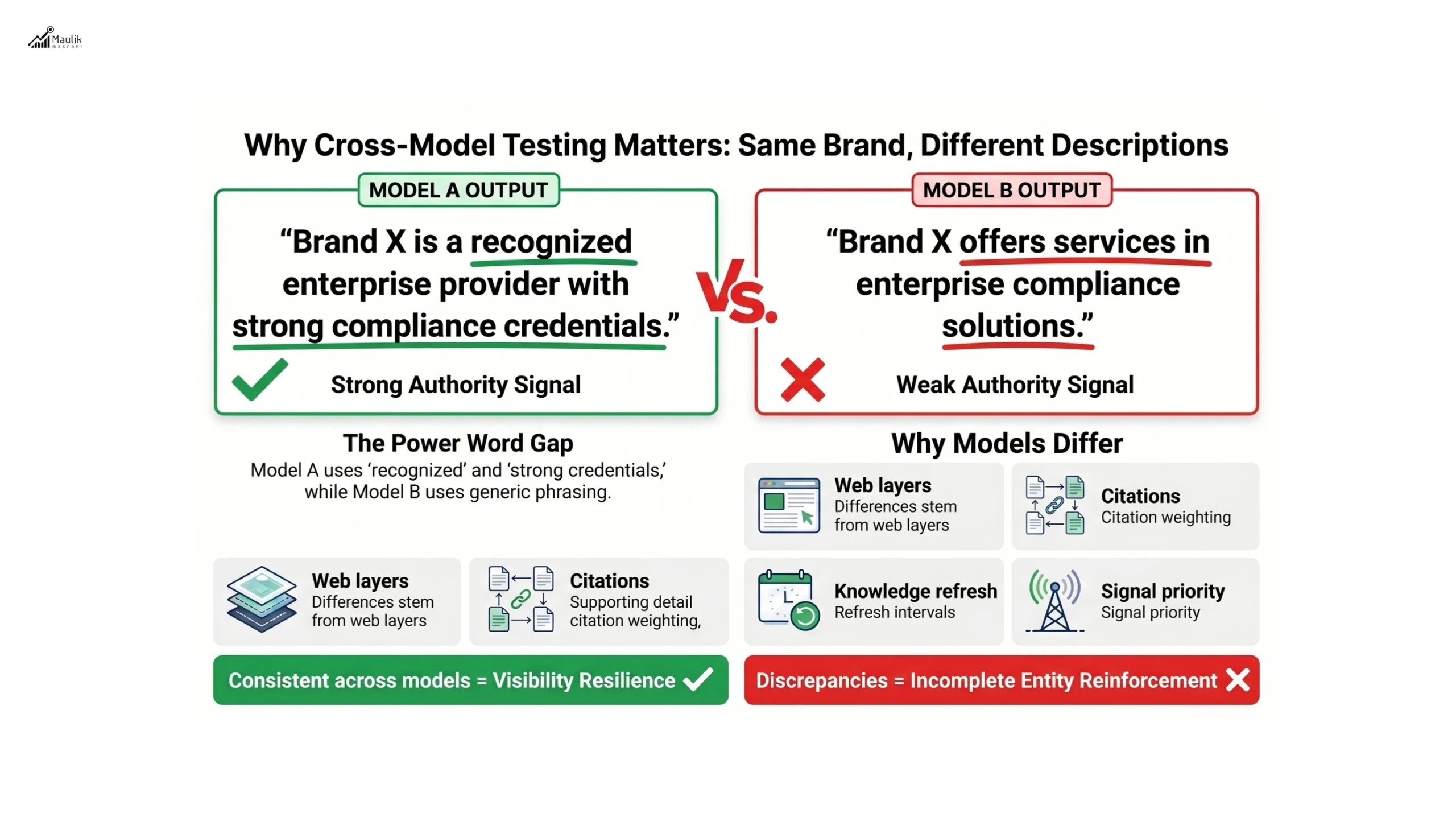 The difference is subtle but strategically significant.
The difference is subtle but strategically significant.
Consistency across models strengthens generative visibility resilience. Discrepancies signal incomplete entity reinforcement.
Sentiment drift indicators
Sentiment rarely shifts dramatically in a single week. Instead, it erodes gradually.
Early drift signals include:
- Replacement of strong descriptors with neutral language
- Increased hedging (“may,” “appears to,” “some users report”)
- Growing emphasis on competitor strengths
- Reduced frequency in “top provider” prompts
- Emergence of risk framing language
Drift often correlates with:
- Outdated content clusters
- Declining third-party validation
- Competitive content expansion
- Shifts in industry narratives
Consider this example:
Quarter 1 Output:
“Brand X is widely trusted for enterprise deployments.”
Quarter 2 Output:
“Brand X provides enterprise services alongside other established providers.”
Quarter 3 Output:
“Brand X is one of several providers in the enterprise market.”
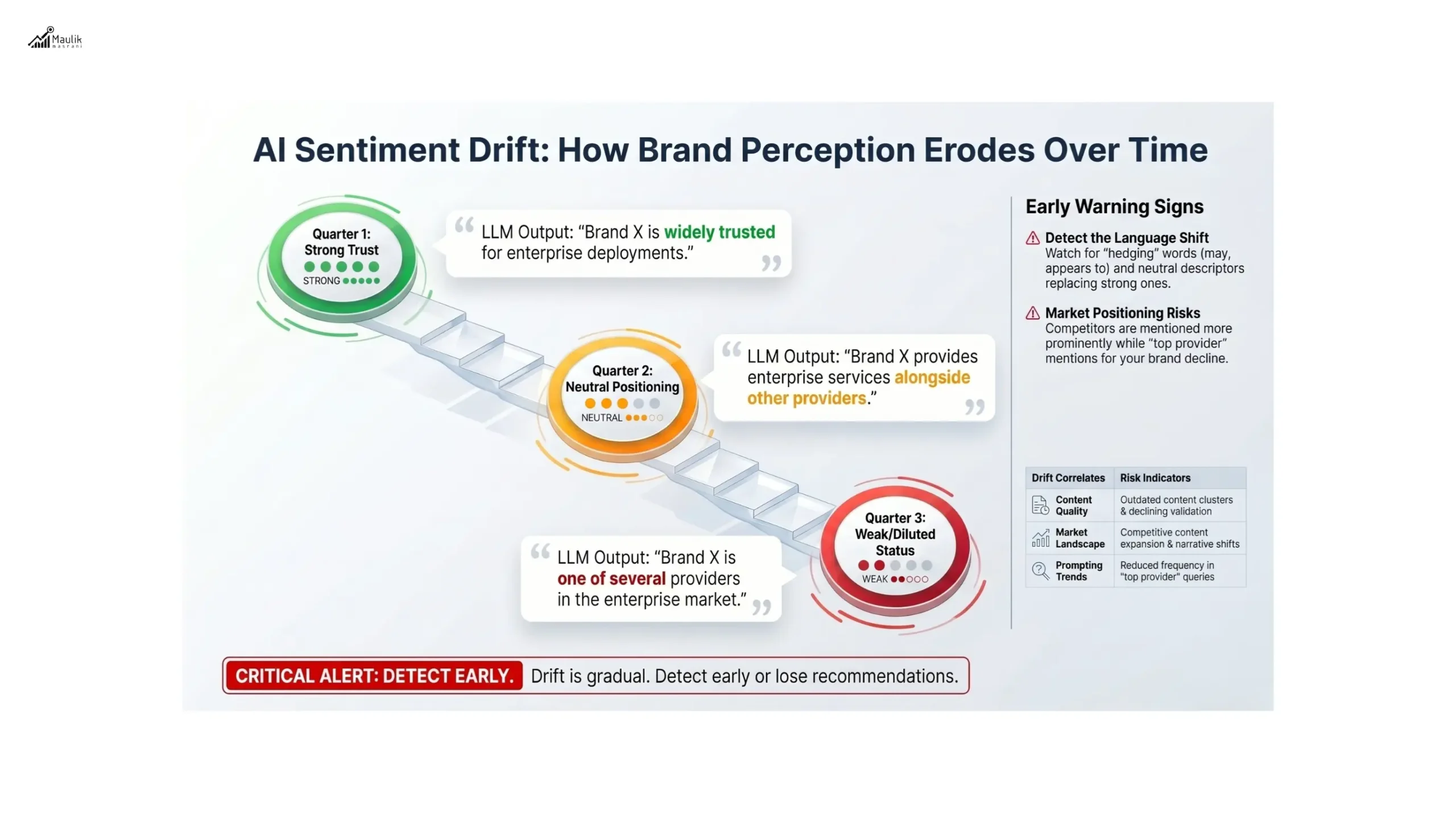 The erosion is incremental but measurable.
The erosion is incremental but measurable.
Detecting drift early prevents recommendation loss.
Correction cycles
Monitoring without action has no strategic value. Correction cycles transform insight into influence.
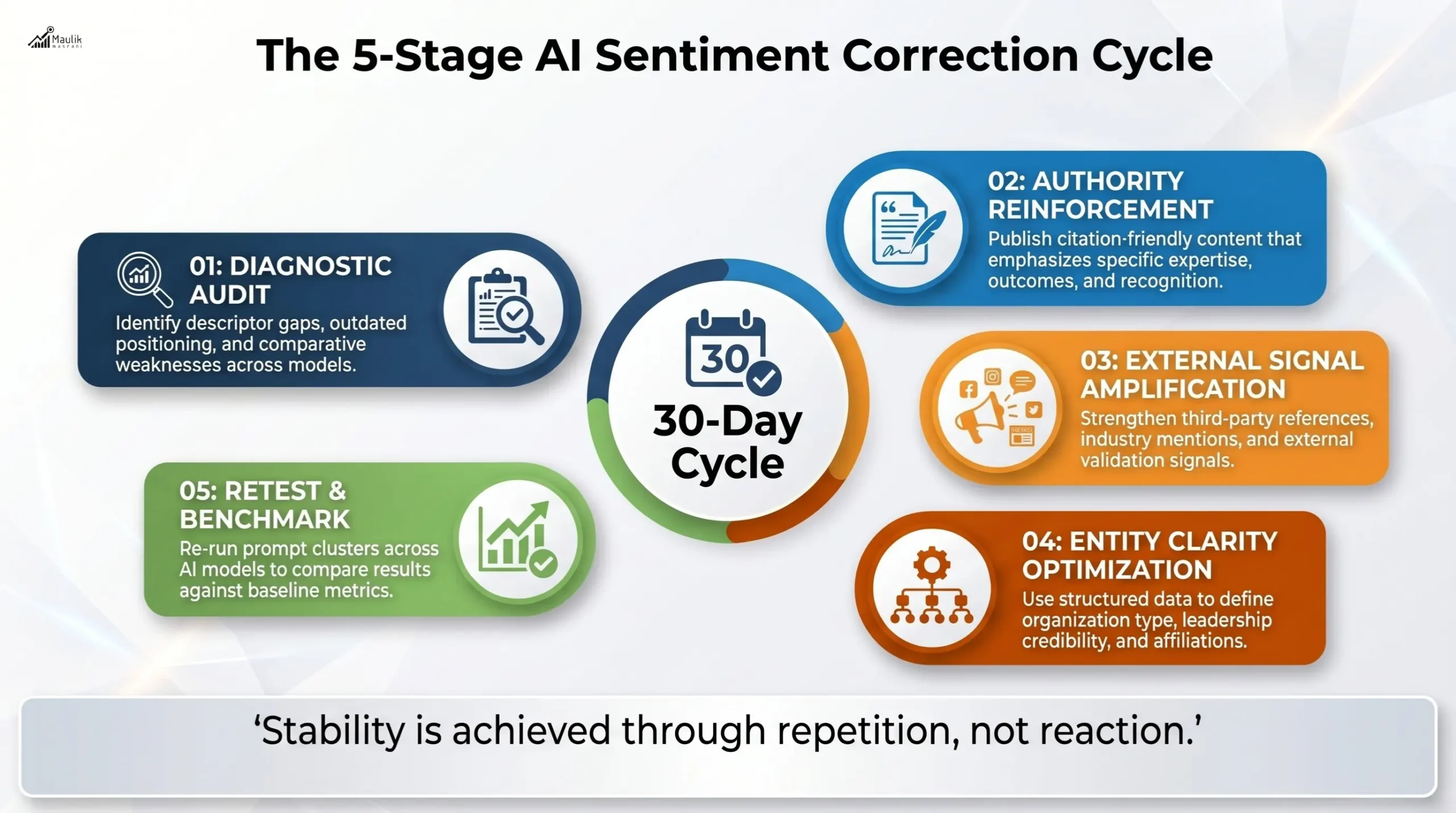
A structured correction cycle includes:
Stage 1: Diagnostic Audit
Identify descriptor gaps, outdated positioning and comparative weaknesses.
Stage 2: Authority Reinforcement
Publish structured, citation-friendly content emphasizing expertise, outcomes and industry recognition.
Stage 3: External Signal Amplification
Strengthen third-party references, industry mentions and validation signals.
Stage 4: Entity Clarity Optimization
Ensure structured data clearly defines organization type, expertise areas, affiliations, awards, and leadership credibility.
Stage 5: Retest & Benchmark
Re-run prompt clusters across models and compare against baseline metrics.
Correction cycles typically operate in 30-day performance windows within an AIO roadmap.
Stability is achieved through repetition, not reaction.
FAQs
How do I track AI sentiment?
Track AI sentiment by running structured prompts across major LLMs, documenting tone and positioning, measuring inclusion frequency, and comparing descriptor strength over time. Combine manual review with automated trend dashboards for consistency.
Can AI sentiment monitoring improve recommendations?
Yes. When weak framing or omission patterns are identified, reinforcement publishing and authority signals can shift how models describe and recommend your brand.
What causes AI sentiment drift?
Common causes include outdated content, reduced citation frequency, competitor content growth, and shifts in industry narratives that reshape association patterns.
How often should sentiment be evaluated?
High-visibility brands should monitor weekly through automation and conduct deeper manual audits monthly, especially in competitive sectors.
Conclusion
As AI search increasingly shapes brand perception, how LLMs describe your company matters as much as where you rank. AI sentiment monitoring helps organizations track tone, detect perception shifts, and maintain strong authority signals in generative results. Within a focused AIO strategy, regularly analyzing sentiment allows brands to identify weak framing early and reinforce their expertise through stronger authority signals.
Consistent monitoring also helps maintain trust across different AI platforms where buyers conduct research. By understanding how AI systems interpret your brand narrative, businesses can ensure their positioning remains credible, visible, and competitive in AI-driven search environments.