AIO experimentation is no longer optional. If you want predictable AI visibility across generative engines, you need structured testing, not assumptions. This guide introduces a data-driven AI optimization testing framework covering hypothesis design, AI answer frequency tracking, cross-model comparisons and a repeatable iteration cycle blueprint. The result: measurable gains in AI answer inclusion, authority reinforcement and performance clarity across LLMs.
AIO Experimentation Framework
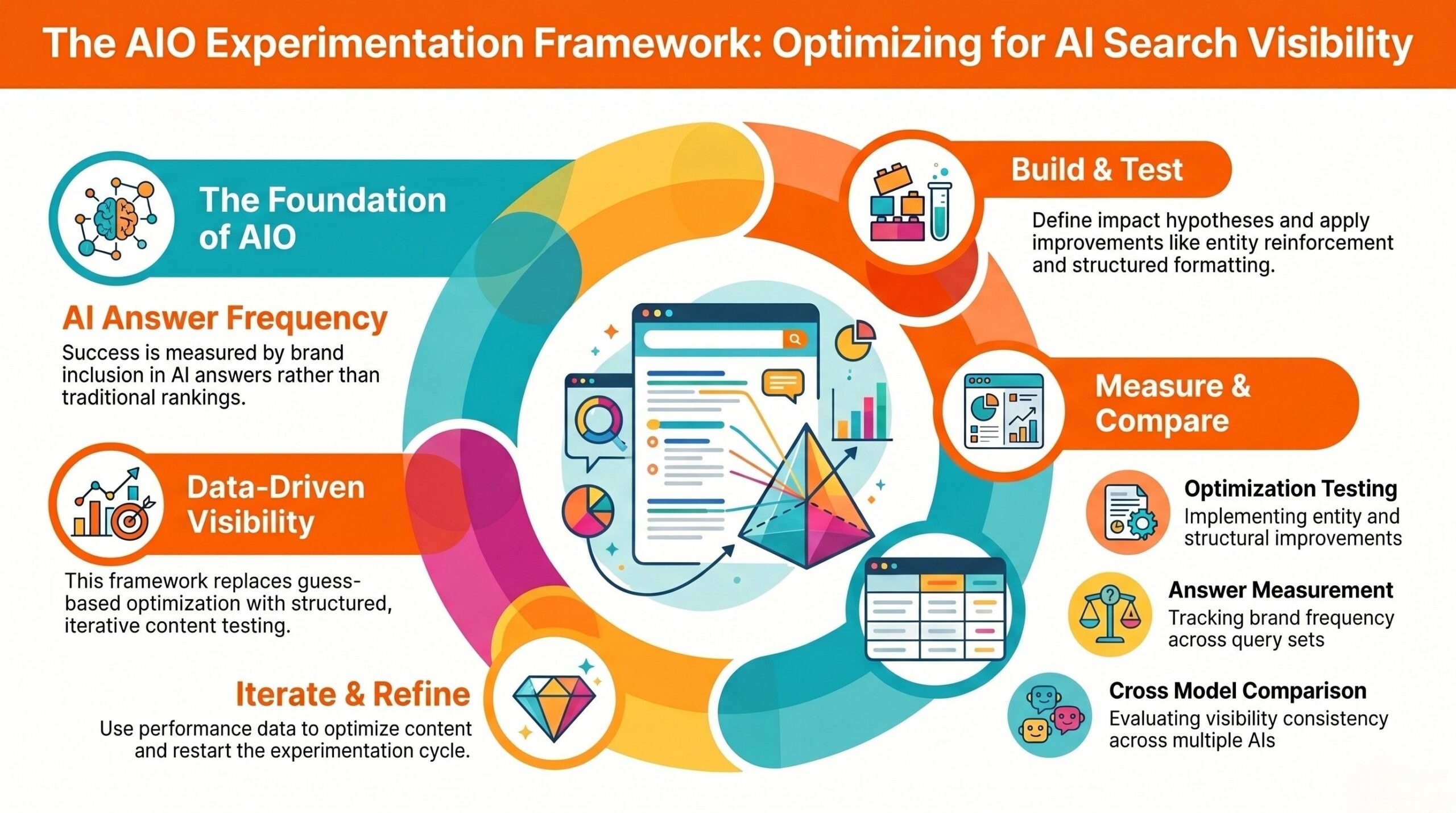
The rise of generative search has fundamentally changed optimization. Rankings alone no longer define visibility. AI-generated answers, citations, summaries and model interpretations now influence brand exposure.
This shift requires AIO experimentation, a systematic process to test how content performs across AI systems, measure inclusion rates and optimize accordingly.
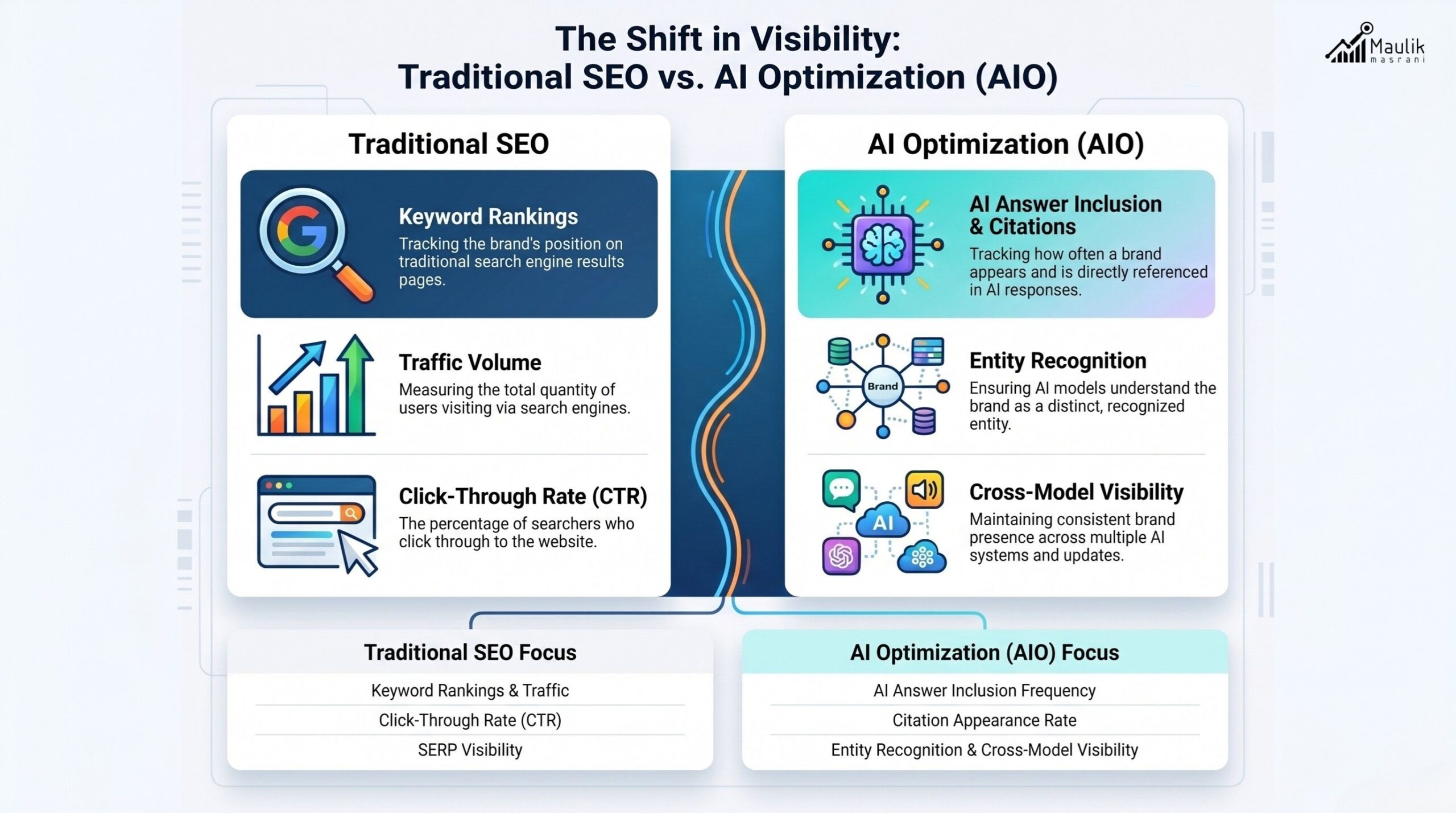
Traditional SEO relies on ranking positions and traffic data. AIO relies on:
- AI answer inclusion frequency
- Citation appearance rate
- Entity clarity strength
- Cross-model consistency
- Contextual interpretation alignment
Without experimentation, optimization becomes guesswork. With a framework, it becomes measurable.
Why AI Optimization Requires Testing
Generative systems behave probabilistically, not deterministically.
Two users can ask identical queries and receive slightly different answers depending on model parameters, prompt framing, context length, or system updates. That variability makes testing essential.
Here’s why structured experimentation matters:
1. AI outputs change over time
Model updates can alter how your content is interpreted. What worked last month may not work today.
2. Citation logic varies across models
Different LLMs prioritize signals differently schema density, structured formatting, clarity of definitions, or entity references.
3. Visibility is distribution-based
Instead of ranking #1, you may appear in 37% of AI responses for a query cluster. Increasing that frequency to 62% is a measurable win.
In other words, AI optimization is not static. It’s iterative. That’s where an AI optimization testing framework becomes mission-critical.
Hypothesis Building for AIO
Every experiment begins with a hypothesis.
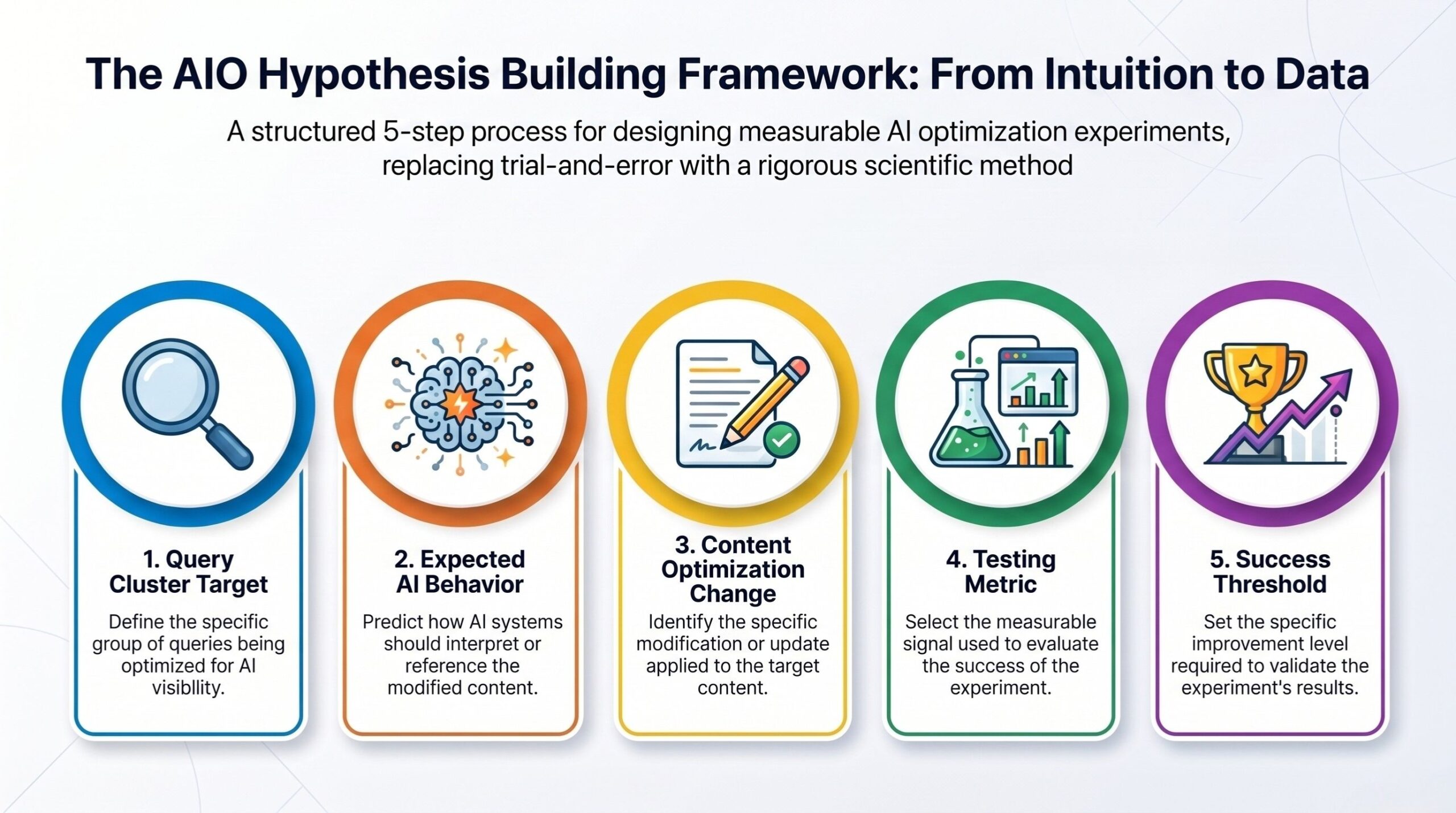
A strong AIO hypothesis includes:
- Query cluster target
- Expected AI behavior
- Specific content modification
- Measurement metric
- Success threshold
Example Hypothesis:
“If we introduce definition-first formatting and structured FAQ schema, AI answer inclusion frequency for ‘enterprise AI audit’ queries will increase by 20% across models.”
This transforms vague optimization into measurable testing.
Effective hypothesis building often focuses on:
- Definition clarity
- Structured formatting
- Entity reinforcement
- Internal topical linking
- Content depth refinement
For example, strengthening internal topic relationships (such as linking to relevant pages like AI SEO manufacturing) can improve contextual association across AI systems.
The key principle:
Do not optimize blindly. Define expected change. Then measure it.
AI Answer Frequency Testing
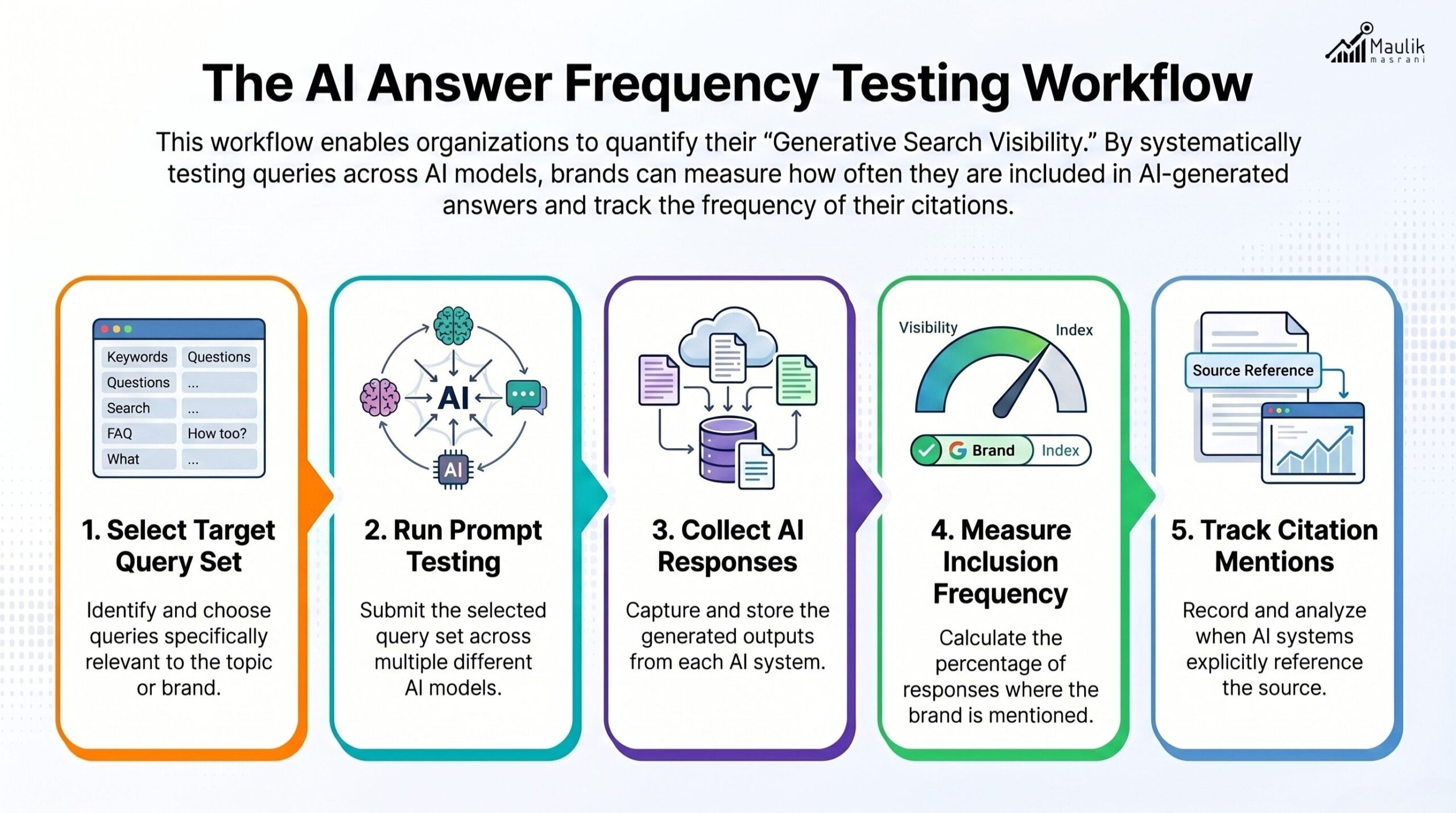
In traditional SEO, we measure rankings. In AIO, we measure answer frequency.
AI answer frequency testing involves:
- Selecting a defined query set
- Running structured prompts across models
- Tracking inclusion rates
- Recording citation mentions
- Measuring consistency over multiple runs
For instance:
- 50 target prompts
- Tested across 3 AI models
- 3 iterations per prompt
- Total of 450 outputs analyzed
Metrics to track:
- Appearance frequency (% inclusion)
- Citation presence
- Direct mention vs implied reference
- Summary dominance
- Positional prominence within response
This resembles generative A/B testing, but instead of comparing two landing pages, you compare structural content variants across AI outputs.
Variant A: Narrative format
Variant B: Definition-first structured format
Variant C: Entity-rich with FAQ schema
Measure which variant increases the answer inclusion probability. Testing cycles should run over multiple weeks to account for model variability.
Cross-Model Comparison Method
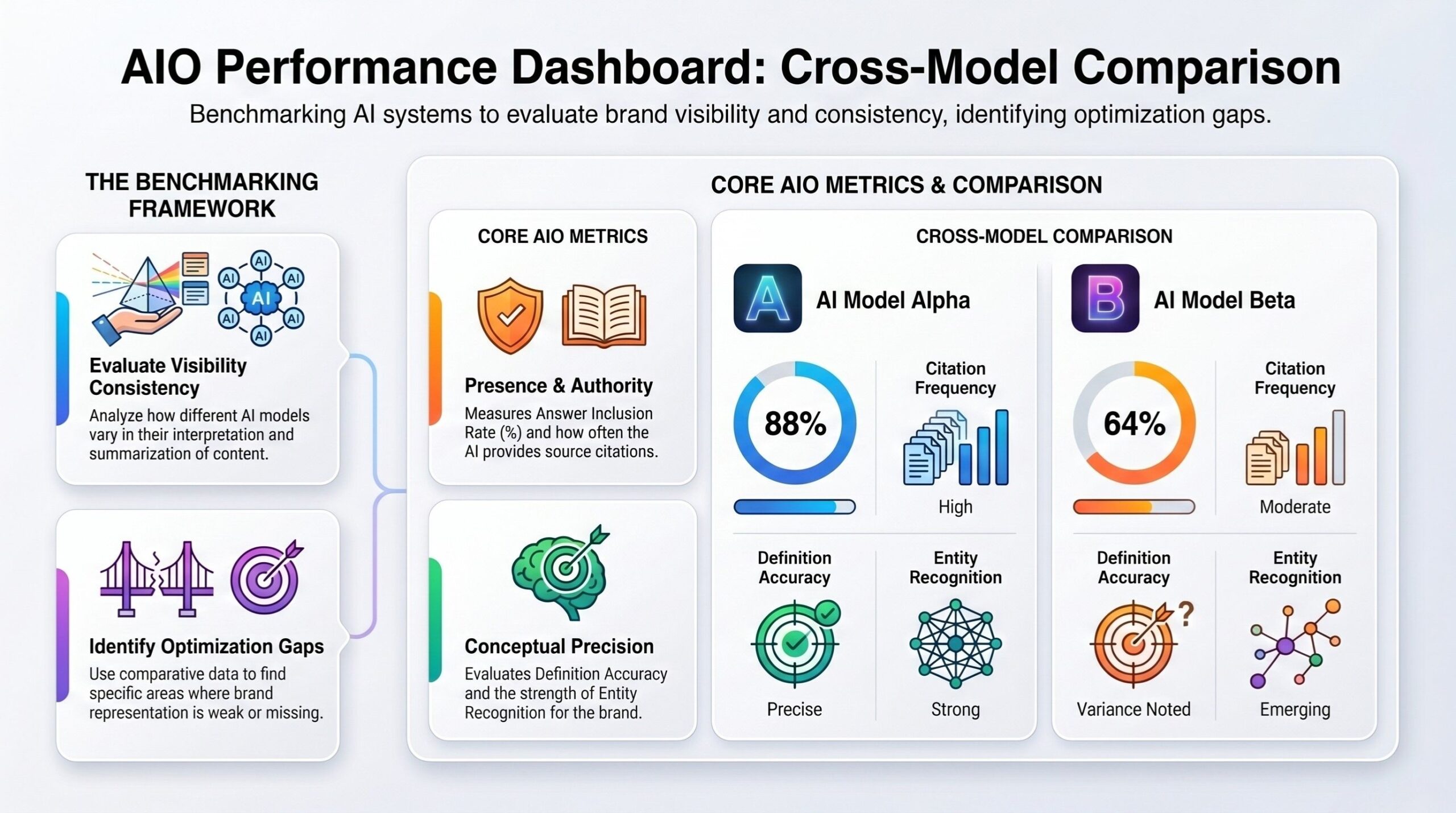
Not all AI systems behave the same.
A cross-model comparison method evaluates:
- Inclusion consistency
- Response tone alignment
- Citation style
- Interpretation stability
If one model consistently includes your brand while another ignores it, that signals structural optimization gaps.
Metric | Model A | Model B | Model C |
Inclusion Rate | 64% | 48% | 59% |
Citation Frequency | 40% | 31% | 35% |
Definition Accuracy | High | Medium | High |
Entity Recognition | Strong | Moderate | Strong |
The comparison framework should include: The objective is not dominance in one model, but stable visibility across ecosystems.
In analytical contexts, third-party benchmarking data (such as aggregated industry research published on platforms like Clutch) can provide baseline expectations for competitive performance.
Cross-model insights often reveal:
- Over-reliance on narrative formatting
- Weak schema structure
- Insufficient topic graph reinforcement
- Inconsistent entity naming
These become optimization levers.
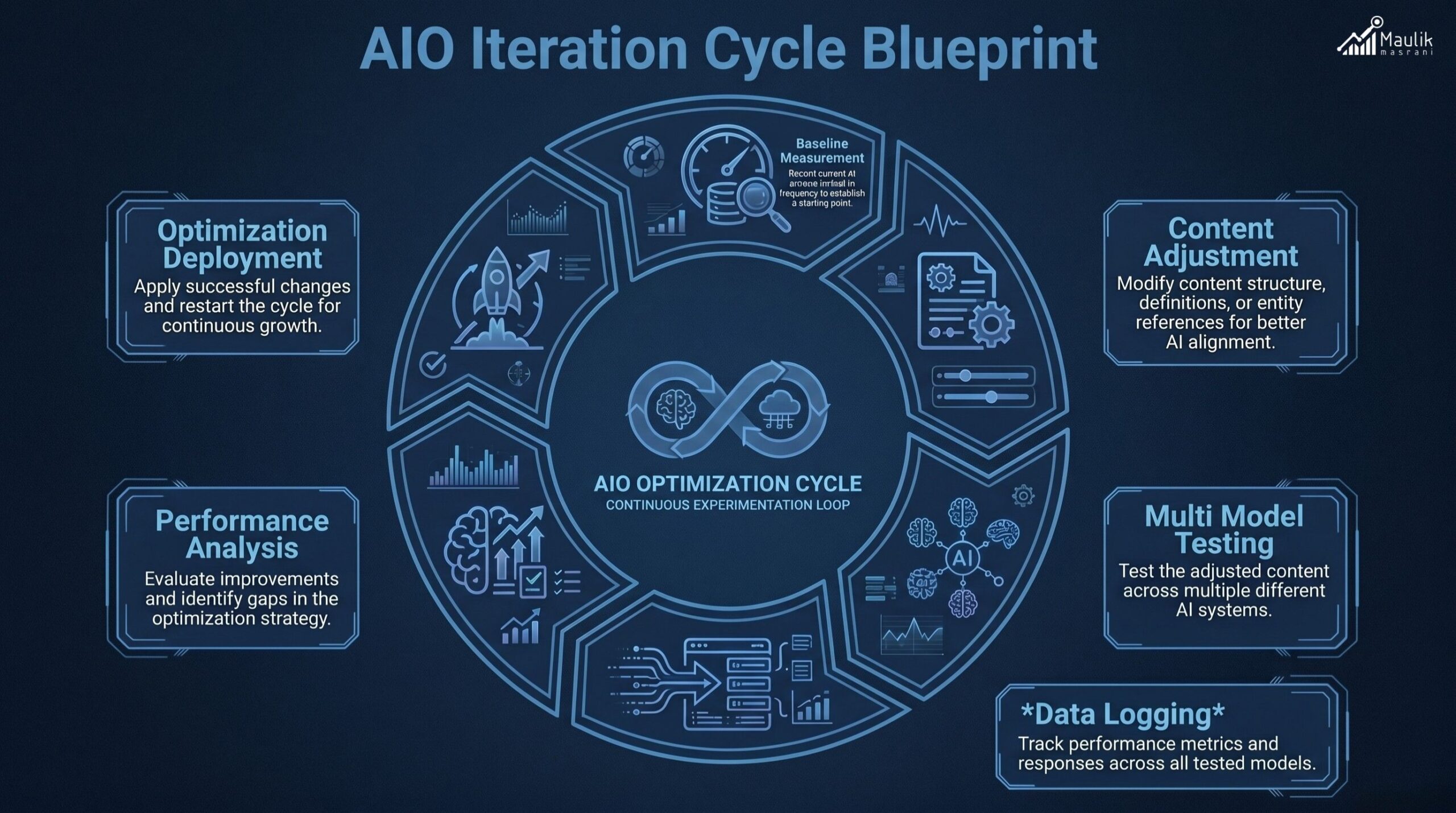
Iteration Cycle Blueprint
AIO experimentation must operate as a loop, not a one-time test.
The iteration cycle includes:
Step 1: Baseline Measurement
Track AI inclusion frequency before changes.
Step 2: Controlled Content Adjustment
Modify one variable at a time: structure, definition placement, FAQ integration, or internal linking density.
Step 3: Multi-Model Testing
Run structured queries across systems.
Step 4: Data Logging
Record frequency, citation style and consistency.
Step 5: Statistical Review
Look for meaningful improvement (minimum 15 -20% frequency lift recommended for validation).
Step 6: Standardization
Apply a successful structure to related content clusters.
Step 7: Revalidation
Re-test after 30–60 days to detect drift.
This blueprint transforms experimentation into a repeatable optimization engine.
Over time, this system builds:
- AI visibility predictability
- Authority reinforcement
- Competitive resilience
- Model-stable inclusion rates
That is the strategic objective of advanced AIO experimentation.
FAQs
How do you test AIO effectiveness?
You test AIO effectiveness by measuring AI answer inclusion frequency, citation presence, cross-model consistency and response stability across structured prompt testing cycles.
What is the difference between AIO and traditional SEO testing?
Traditional SEO measures rankings and traffic. AIO measures generative answer inclusion, citation rate, entity clarity and model consistency across AI systems.
How often should AIO experiments run?
AIO experiments should run continuously in 30–60 day cycles to account for model updates and AI drift.
Is generative A/B testing reliable?
Yes, when run across structured prompts, multiple models and repeated cycles, generative A/B testing provides statistically meaningful optimization insights.
Conclusion
AIO success does not come from assumptions; it comes from disciplined experimentation. When you test hypotheses, measure AI answer frequency, compare models and iterate systematically, visibility becomes predictable rather than accidental. The brands that treat AIO experimentation as an ongoing optimization cycle will steadily improve inclusion rates, strengthen authority signals and maintain stable performance across evolving generative systems.
In a landscape where AI outputs shift continuously, structured testing becomes your competitive safeguard. A repeatable experimentation framework ensures you are not reacting to changes but strategically adapting to them with clarity, data and confidence.