
Large language models sometimes produce incorrect information about companies, products, or individuals because their knowledge is derived from fragmented entity signals across the web. An effective LLM correction framework helps diagnose broken entity links, repair structured data, reinforce authoritative sources and align information across platforms.
When combined with modern AIO, AEO, and GEO strategies, businesses can stabilize their entity identity so generative search systems consistently return accurate responses.
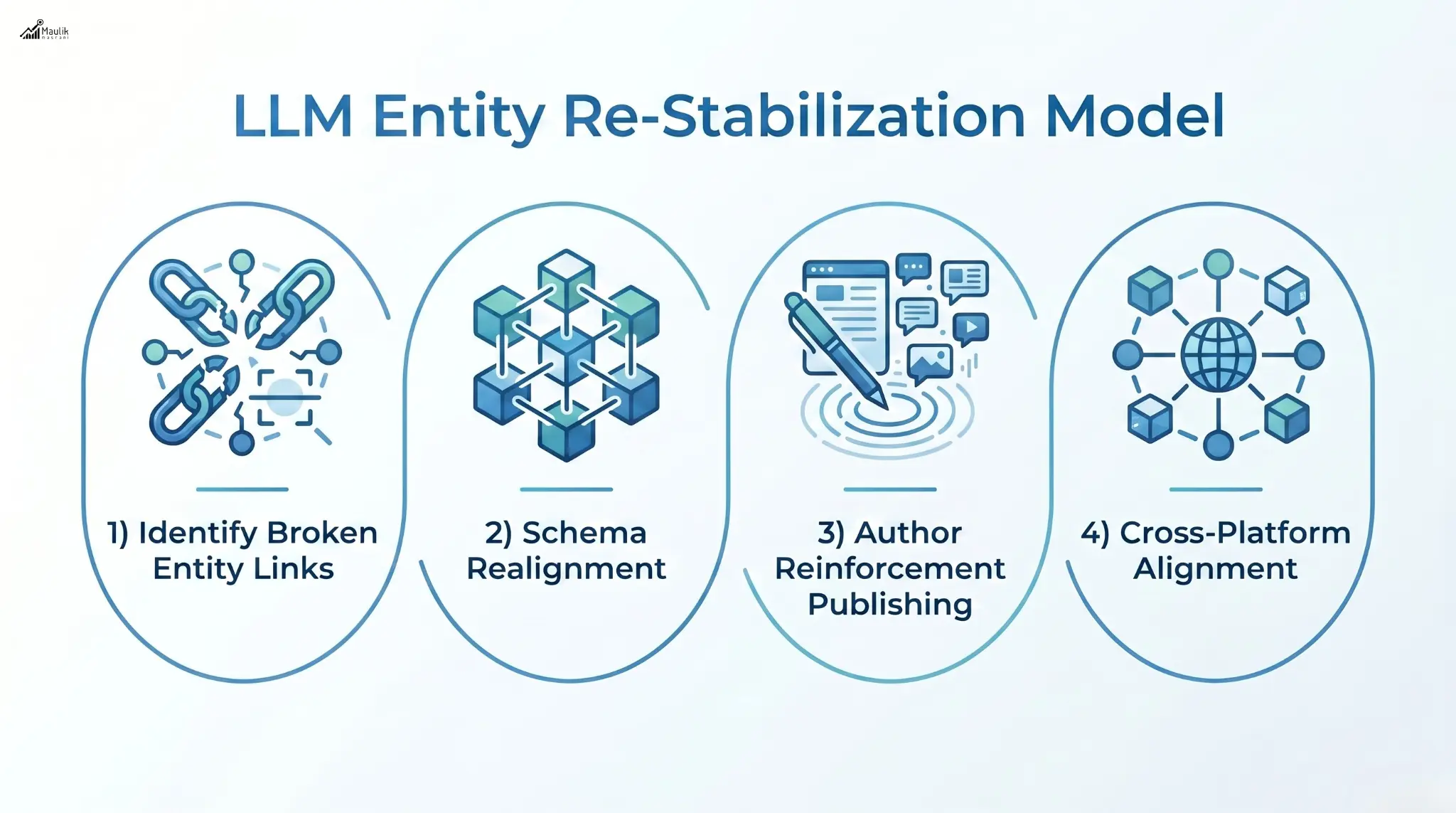
LLM Correction Framework
Generative search is transforming how information is discovered and interpreted online. Instead of indexing pages and ranking them like traditional search engines, modern AI systems synthesize knowledge from multiple sources to generate direct answers.
While this improves user convenience, it also introduces a new challenge: misinformation generated by AI systems. Large language models may unintentionally combine outdated information, fragmented data sources, or unrelated entities that share similar names.
For example, a brand that recently restructured its leadership team may still see outdated executive information appear in AI answers. In other cases, companies with similar names may be incorrectly merged in generative responses.
The LLM correction framework addresses this problem through an entity re-stabilization model. Instead of correcting individual pages, the framework repairs the broader ecosystem of signals that AI models rely on. This includes structured data, authoritative publishing, entity consistency, and cross-platform alignment.
Organizations implementing this framework often integrate it with modern Artificial Intelligence Optimization (AIO) and Generative Engine Optimization (GEO) strategies. These approaches ensure that AI models consistently associate the correct information with the right entity.
Identifying Broken Entity Links
The first stage of the LLM correction framework focuses on identifying where misinformation originates.
Large language models rely on entity relationships extracted from structured content, knowledge graphs and authoritative sources. If these relationships break or become inconsistent, the model may generate incorrect associations.
Common causes of broken entity links include:
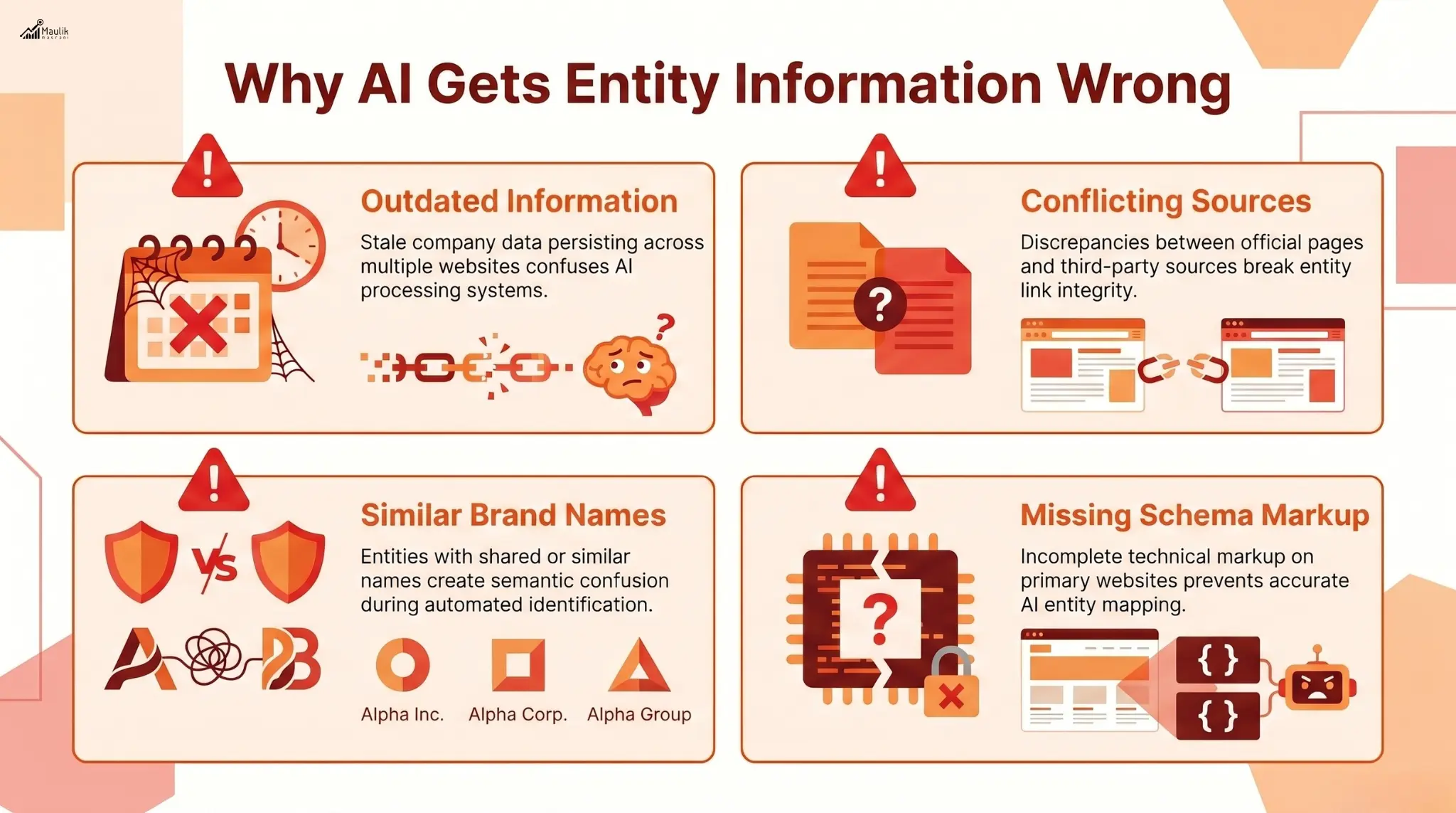
- Outdated company information across multiple websites
- Conflicting details between official pages and third-party sources
- Similar brand names create entity confusion
- Incomplete schema markup on primary websites
A practical method for detecting these issues involves cross-model testing. Teams can run the same query across different AI systems, such as ChatGPT, Gemini, or Perplexity and compare responses.
If incorrect information appears consistently across multiple models, it usually indicates that the problem originates from widely distributed entity signals rather than a single data source.
Advanced monitoring workflows within GEO strategies often track how AI systems describe an entity over time. These monitoring systems identify patterns such as incorrect leadership names, outdated product offerings, or inaccurate company descriptions.
Once these broken entity relationships are identified, organizations can begin correcting the signals at their source.
Schema Realignment Process
Structured data plays a major role in how AI systems interpret facts. Schema markup provides machine-readable signals that clarify relationships between entities.
If generative systems produce incorrect information, one of the first corrective actions is performing a schema audit.
A schema realignment process usually involves the following steps:
- Reviewing existing schema types such as Organization, Person, Product, and FAQPage
- Ensuring all structured data references the correct entity attributes
- Aligning schema identifiers across pages to maintain entity consistency
- Updating structured data when company details change

For instance, if a company relocates its headquarters or updates leadership roles, those changes must appear within the organization schema. Without these corrections, generative systems may continue referencing outdated information.
Schema alignment also strengthens Answer Engine Optimization (AEO) strategies. Since AI systems prefer extracting concise factual statements, a well-structured schema helps them retrieve accurate information more reliably.
When structured data is implemented consistently across the website, AI systems gain clearer signals about the entity they are interpreting.
Author Reinforcement Publishing
Another key component of the LLM correction framework is reinforcing the author’s authority.
Generative AI systems place strong trust signals on content written by identifiable experts. When authoritative authors publish consistent information about an entity, those signals strengthen the credibility of the data.
Author reinforcement publishing typically includes:
- Publishing expert-led articles that clarify factual information
- Updating author profiles with consistent credentials and affiliations
- Connecting content pieces through author schema markup
- Creating authoritative explanations of services or products
For example, if AI systems incorrectly describe a company’s service offerings, publishing expert-led articles explaining those services can help reshape how AI models interpret the entity.
This strategy is particularly effective within AIO frameworks, where content authority and entity clarity play a critical role in how AI systems generate responses.
Over time, authoritative publications become reference points that generative models use to validate information.
FAQ Injection Technique
Large language models frequently extract answers from structured Q&A content because it mirrors how users interact with AI.
The FAQ injection technique focuses on strategically publishing structured question-and-answer sections across authoritative pages.
Typical benefits of FAQ injection include:
- Providing clear answers to common AI-generated misconceptions
- Increasing the likelihood of generative systems extracting accurate responses
- Strengthening entity clarity through FAQ schema markup
- Supporting AEO strategies for conversational search environments
For example, if AI systems frequently misinterpret a brand’s service model, a dedicated FAQ section can directly address those misunderstandings.
Questions such as “What services does the company provide?” or “Who leads the organization?” help AI systems retrieve concise factual responses.
When implemented with FAQPage schema markup, these sections create strong machine-readable signals that guide AI systems toward accurate answers.
Cross-Platform Correction Alignment
Correcting misinformation within a single website rarely solves the problem entirely. Generative systems collect data from many sources across the web.
For this reason, the final stage of the entity restabilization model focuses on cross-platform correction alignment.
This process involves ensuring that the same factual information appears consistently across digital platforms.
Key areas requiring alignment include:
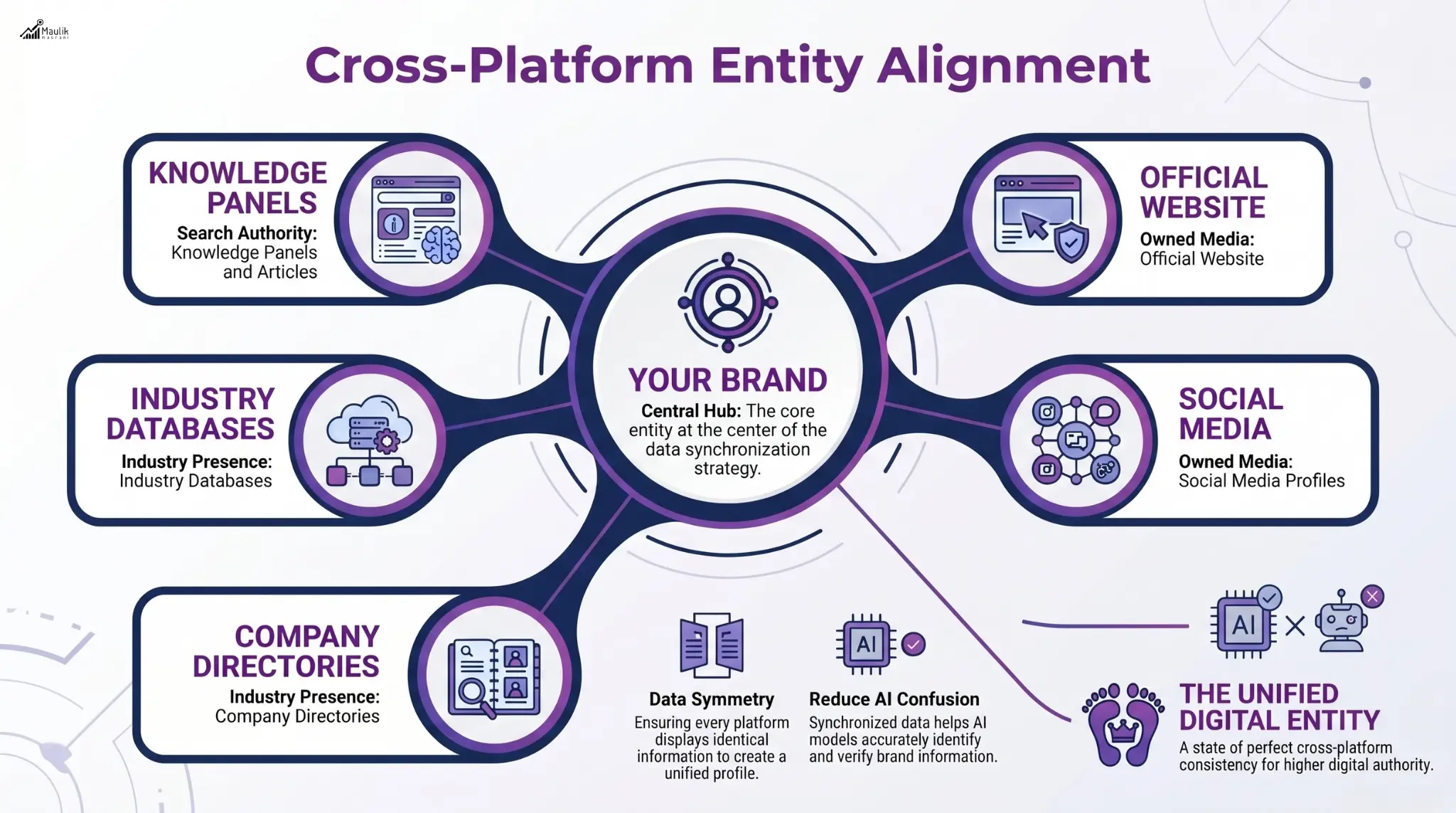
- Official websites
- Social media profiles
- company directories
- industry databases
- knowledge panels and articles
For example, if a company updates its leadership team or service offerings, those changes must appear consistently across all digital channels.
Organizations implementing GEO strategies often maintain centralized knowledge repositories that serve as the source of truth for entity information.
These repositories ensure that content teams, marketing departments, and technical teams all publish consistent information.
By aligning signals across platforms, brands reduce confusion within AI knowledge graphs and help generative systems recognize the correct entity relationships.
FAQs
How do I correct wrong AI outputs?
Correcting AI outputs requires identifying incorrect entity signals, updating structured data, publishing authoritative corrections and ensuring information consistency across digital platforms.
Why do LLMs generate misinformation about brands?
LLMs synthesize information from multiple datasets and sources. If those sources contain outdated or conflicting information, the AI system may generate incorrect responses.
Does schema markup help fix AI misinformation?
Yes. Structured data provides machine-readable signals that clarify entity relationships, helping generative systems interpret factual information more accurately.
How long does AI misinformation correction take?
The correction timeline varies depending on how widely incorrect information is distributed. Consistent updates across authoritative sources typically accelerate the stabilization process.

Conclusion
AI-driven search systems rely heavily on entity relationships and structured knowledge signals, which means misinformation can spread quickly when those signals become inconsistent. The LLM correction framework provides a systematic method for restoring accuracy by identifying broken entity connections, realigning schema data, reinforcing authoritative publishing, and synchronizing information across platforms.
When organizations apply this model alongside modern AIO, GEO, and AEO strategies, they strengthen the reliability of their digital identity within generative search ecosystems. Over time, consistent entity reinforcement helps AI systems replace inaccurate outputs with verified and authoritative information.