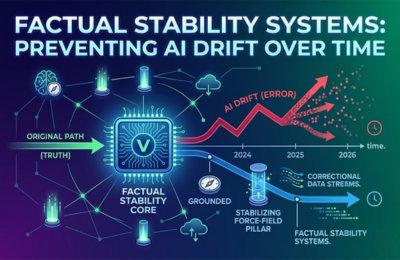
AI-generated and AI-indexed content can slowly change in meaning, accuracy, or context over time, a phenomenon known as drift. A factual stability AI system prevents this by continuously monitoring claims, validating entities, and re-verifying structured data. This guide explains what AI drift is, why it happens, and how to implement AI drift prevention and content consistency monitoring frameworks that keep your information accurate across search engines and large language models.
Factual Stability Systems
Artificial intelligence systems do not remain static. Search engines evolve. Language models retrain. Knowledge graphs update. Content gets edited.
Over time, these changes can introduce inconsistencies, outdated facts, or subtle distortions in meaning. This is where factual stability AI becomes mission-critical.
A factual stability system ensures that your content maintains:
- Accuracy across versions
- Entity consistency across platforms
- Alignment with evolving data sources
- Controlled updates rather than uncontrolled drift
In AI-driven search environments, stability is not optional. It is infrastructure.
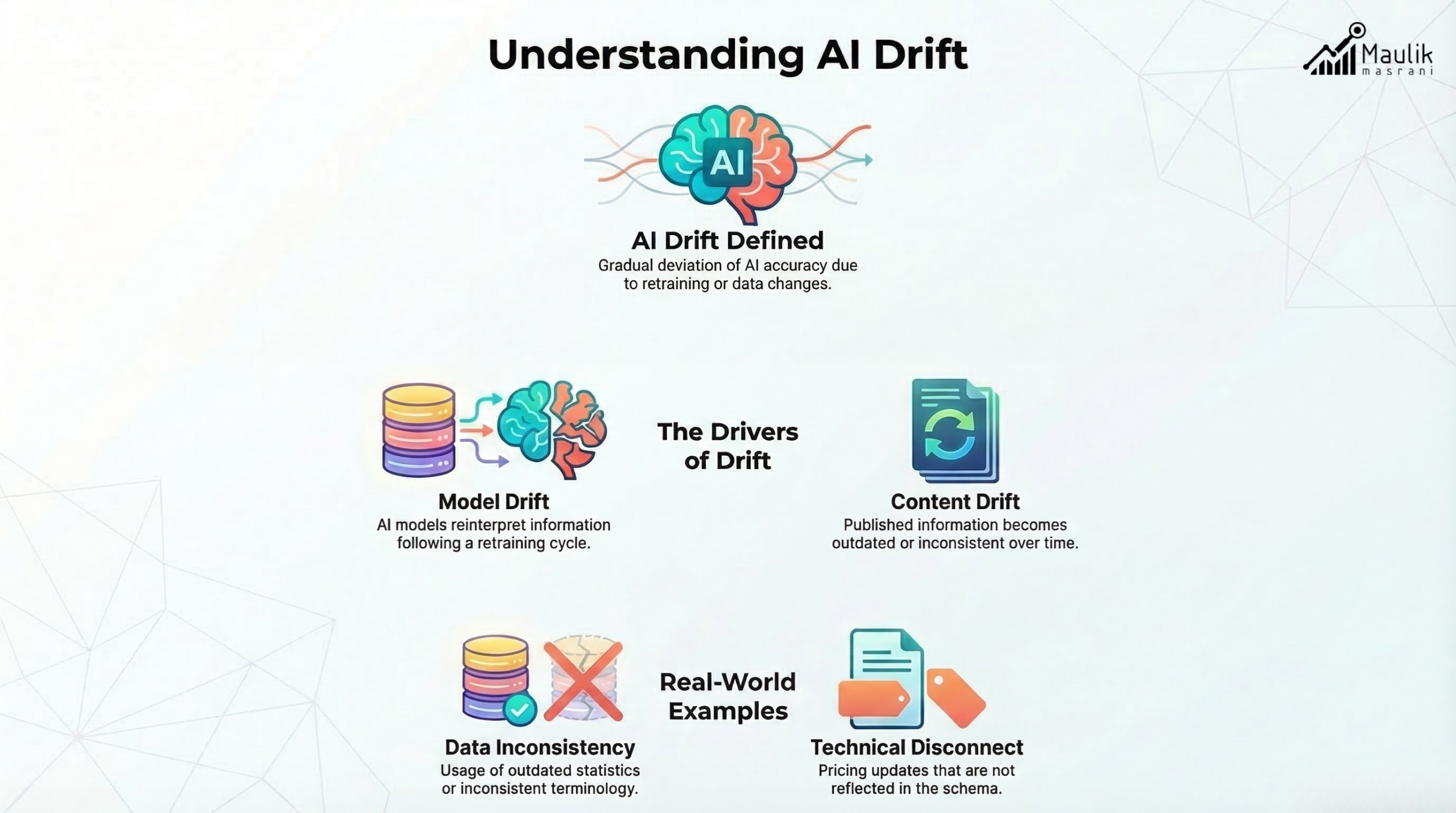
What is AI drift?
AI drift refers to the gradual deviation of information from its original, verified state. It occurs when:
- Training data changes
- External sources update
- Algorithms adjust ranking or retrieval logic
- Content is modified without re-validation
There are two primary forms:
1. Model Drift
When AI systems change their interpretation of information due to retraining or updated embeddings.
2. Content Drift
When published content gradually becomes outdated or inconsistent with current data.
For example:
- A pricing page was updated internally, but not reflected in the structured schema.
- A statistic cited in 2022 that is no longer accurate in 2026.
- An entity name change that is inconsistently reflected across blog posts.
In large ecosystems, this compounds quickly.
According to research from MIT on machine learning systems maintenance, drift is one of the most common causes of long-term performance degradation in AI-dependent environments.
Drift does not usually happen suddenly. It accumulates.
Causes of misinformation over time
Drift is rarely malicious. It is systemic.
Here are the most common drivers:
1. External Data Changes
Statistics, regulations, or product features evolve. If not periodically reviewed, previously accurate statements become incorrect.
Example: A market share statistic sourced from Statista may change annually. Without re-validation, your content becomes outdated.
2. Entity Fragmentation
Different pages refer to the same concept in different ways, leading to semantic inconsistency.
For instance:
- “AI Optimization”
- “Artificial Intelligence Optimization”
- “AIO framework”
Without content consistency monitoring, AI systems may treat these as separate or loosely connected concepts.
3. Structured Data Mismatch
Schema markup might contradict the on-page text.
Example:
- Article updated with new pricing
- The JSON-LD schema still reflects old values
This creates trust erosion across AI crawlers.
4. Algorithmic Reinterpretation
Large language models retrain periodically. Retrieval patterns change. Summaries generated by AI tools may emphasize outdated subpoints.
Platforms such as Google and OpenAI continuously refine ranking and reasoning systems. If your information is not monitored, representation may drift even if your content remains unchanged. This is why AI drift prevention requires an active system, not passive publishing.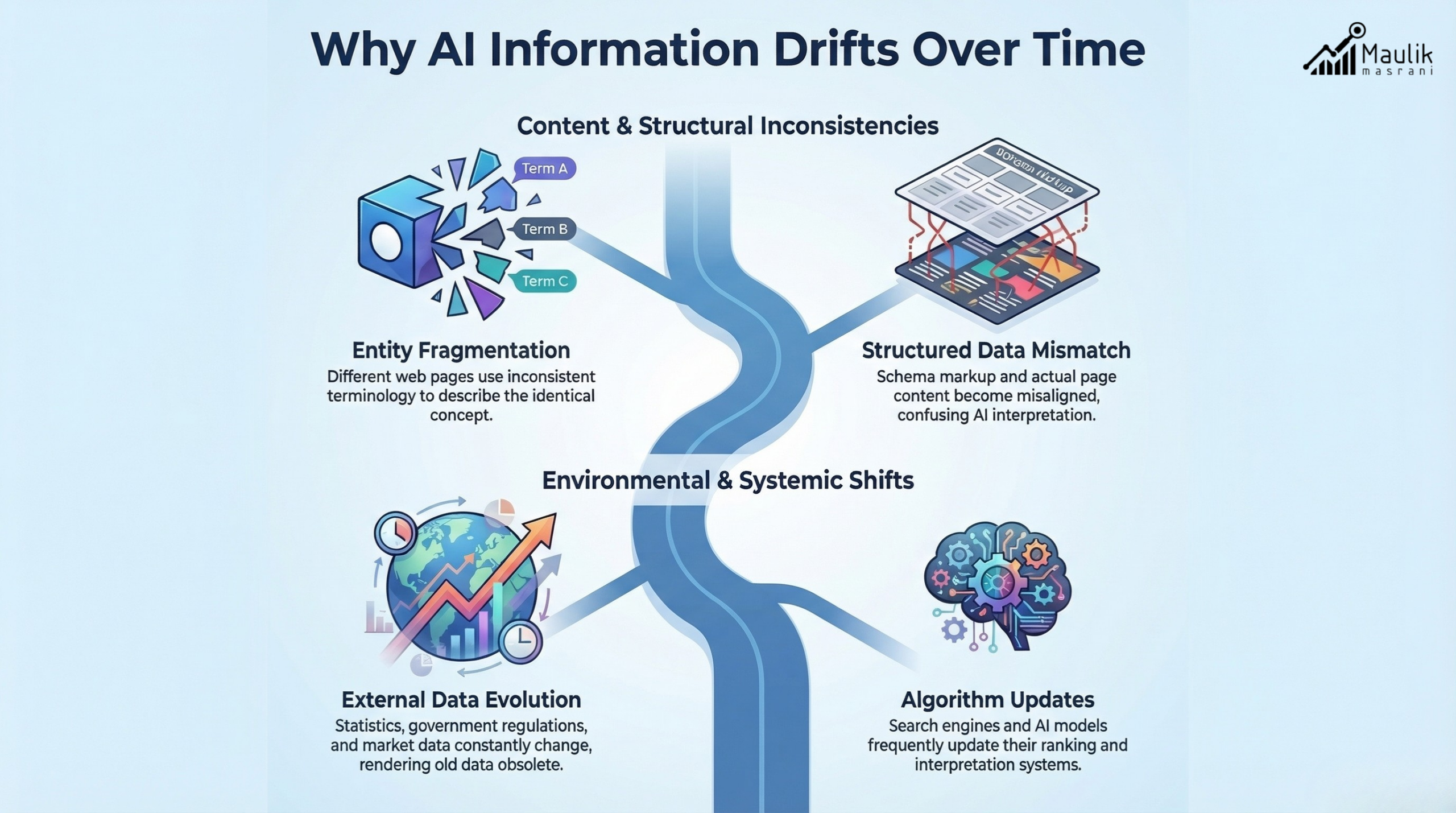
Monitoring tools
Preventing drift begins with detection. You cannot correct what you do not measure.
A strong factual stability AI framework includes the following monitoring layers:
1. Claim Tracking Matrix
Create a centralized log of:
- All statistics
- All data points
- All third-party citations
- Version history
Each claim should have:
- Source URL
- Publication date
- Last validation date
This converts static content into trackable assets.
2. Entity Consistency Scanner
Audit:
- Terminology variations
- Brand naming conventions
- Product labels
- Internal linking structures
Tools like structured search operators and semantic crawlers can help identify mismatches across large content libraries.
3. AI Representation Testing
Periodically query:
- AI chat systems
- Generative search summaries
- Featured snippet previews
Evaluate:
- How your brand is summarized
- Which facts are cited
- Whether outdated information appears
This step is essential for real-world AI drift prevention.
4. Schema Validation Audits
Run regular structured data validation checks.
Use:
- Rich results testing tools
- JSON-LD inspection tools
- Manual code comparison
Structured data discrepancies are a frequent source of AI misinterpretation.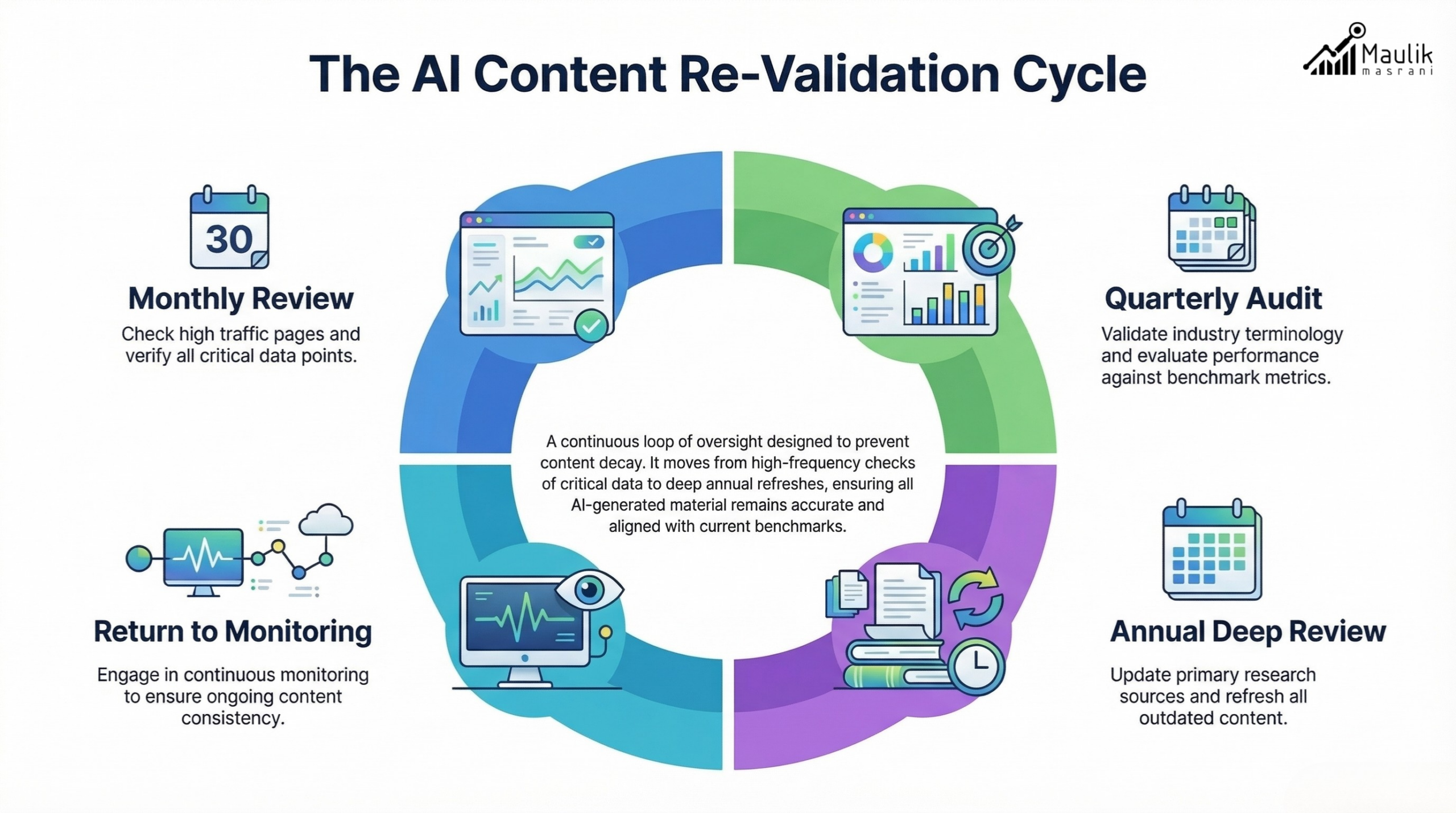
Periodic re-validation framework
Stability requires cadence.
A practical re-validation cycle includes:
Monthly:
- Check high-traffic pages
- Validate top statistics
- Review pricing or regulatory references
Quarterly:
- Re-evaluate entity definitions
- Update benchmark metrics
- Cross-check the schema against the page content
Annually:
- Comprehensive content consistency monitoring audit
- Replace outdated research
- Consolidate fragmented terminology
This layered system prevents long-term compounding errors.
Consider implementing a “content expiration flag.”
Each fact or statistic receives a timestamp. When it reaches its validation threshold, it enters review mode.
This is not about rewriting everything. It is about protecting signal integrity.
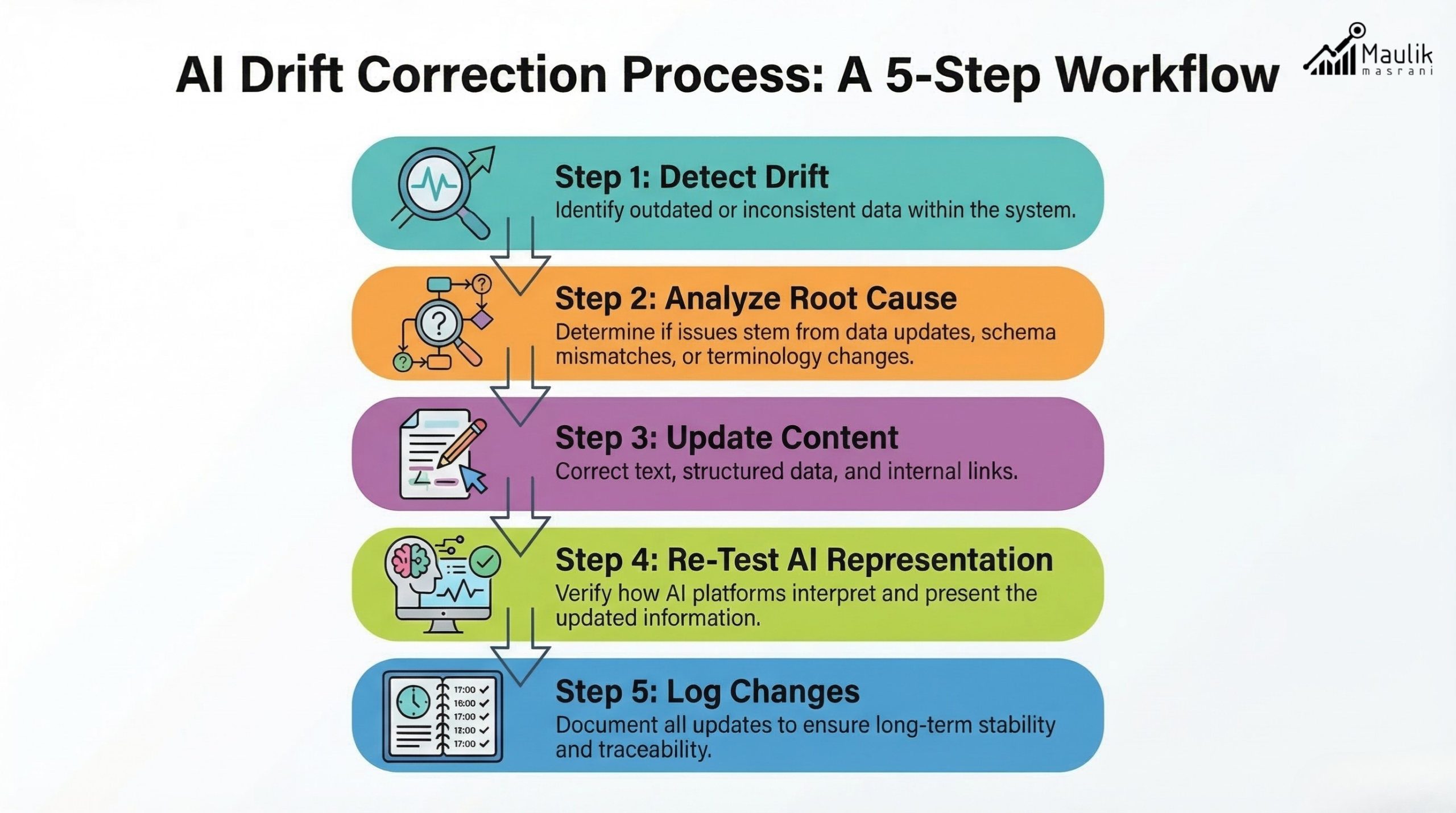
Drift correction model
Even with prevention, drift will occasionally occur. Correction must be systematic.
A robust correction model includes:
Step 1: Drift Detection
Identify mismatch:
- Outdated stat
- Schema inconsistency
- AI misrepresentation
Step 2: Root Cause Analysis
Was it:
- Internal update failure?
- Source update?
- Terminology shift?
- Algorithmic reinterpretation?
Step 3: Controlled Update
- Update content
- Update schema
- Update internal links
- Document version change
Step 4: Re-Test AI Representation
Re-query AI tools. Confirm alignment.
Step 5: Log Resolution
Maintain a change log for future audits.
Over time, this builds resilience.
The goal of factual stability AI is not just accuracy today. It has been accurate over the years.
FAQs
What is AI drift?
AI drift is the gradual deviation of content or model interpretation from its original, accurate state due to retraining, data updates, or content modifications over time.
How does factual stability AI prevent misinformation?
It continuously monitors claims, validates data sources, audits structured schema, and re-tests AI representation to ensure long-term accuracy.
How often should content be re-validated?
High-impact pages should be reviewed monthly, broader audits quarterly, and full content consistency monitoring annually.
What is content consistency monitoring?
It is the structured process of tracking terminology, data points, schema, and AI summaries to prevent fragmentation and misinformation across platforms.
Conclusion
AI systems evolve constantly, and without structured oversight, even accurate content can drift over time. Implementing factual stability AI with consistent monitoring and re-validation ensures your information remains reliable, aligned, and trusted across search and generative platforms.
Organizations that prioritize AI drift prevention and content consistency monitoring build durable credibility. In an environment where machines summarize and interpret your content at scale, factual stability is not just maintenance; it is strategic protection for long-term authority.