
AI hallucinations happen when language models prioritize fluent answers over verified truth. This guide explains why hallucinations occur, how to detect risk areas and what concrete correction and reinforcement techniques prevent LLMs from making up facts about you. The focus is on practical frameworks, grounding, correction loops and monitoring so your brand stays factually aligned across AI systems.
Preventing Hallucinations
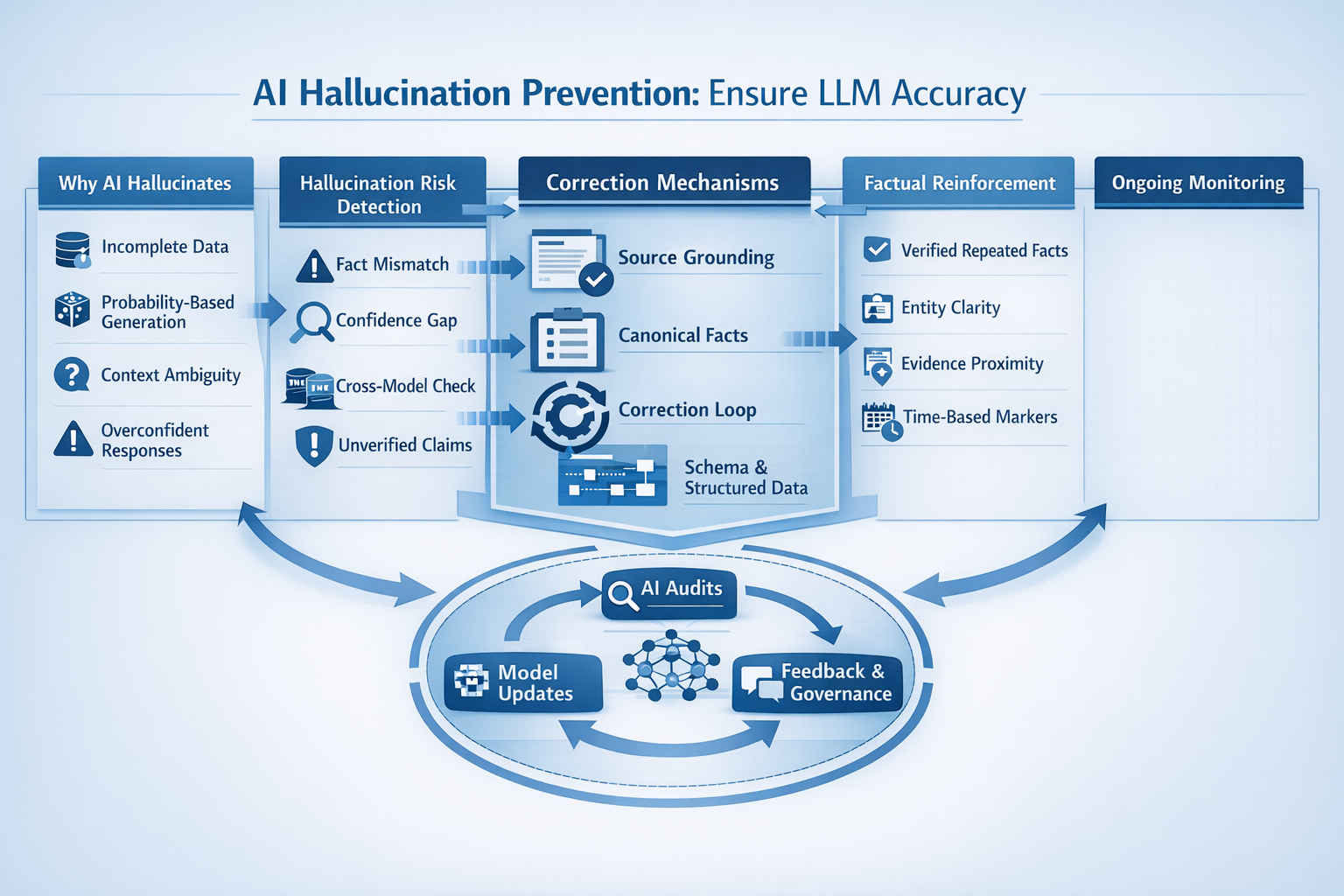
Hallucinations are one of the biggest barriers to trusting large language models. When an LLM invents credentials, misstates company details, or blends unrelated facts, the problem is rarely malicious it is architectural.
Hallucination prevention is not about forcing AI to “be careful.” It is about designing systems, content and signals that constrain generation toward verifiable truth. Brands that ignore this risk often discover incorrect information being repeated across ChatGPT, Gemini, Claude and search-driven AI summaries.
The good news: hallucinations are predictable, detectable and correctable when approached systematically.
Why AI Invents Facts
Language models are probabilistic systems. They generate the most likely next token, not the most accurate statement. Hallucinations emerge when probability outruns evidence.
Core causes behind hallucinations
- Training-data gaps: When models lack direct knowledge, they infer patterns instead of facts.
- Overgeneralization: LLMs extrapolate from similar entities or industries.
- Authority mimicry: Confident tone is learned behavior, not proof of accuracy.
- Context compression: Long prompts or ambiguous inputs dilute factual anchors.
- Reward optimization: Many models are optimized for helpfulness and fluency, not strict verification.
Research summarized in the Anthropic hallucination papers highlights a key insight: hallucinations increase when models are forced to answer beyond grounded knowledge, especially under time or token constraints.
This is why hallucination prevention starts before generation at the data, prompt and authority layers.
Detecting Hallucination Risks
You cannot prevent what you do not measure. Detection is the first operational step.
Common hallucination risk zones
- About pages and bios: AI often fabricates awards, years, or affiliations.
- Technical claims: Specs, certifications and standards are frequently approximated.
- Comparisons: Models blend competitors’ features into your brand.
- Timelines: Dates and version histories drift easily.
- Low-entity-density content: Pages without clear factual anchors invite invention.
Practical detection methods
- Cross-model testing: Ask the same question across multiple LLMs and compare variance.
- Answer decomposition: Break AI responses into atomic claims and validate each.
- Confidence mismatch analysis: High-confidence tone with low-source visibility is a red flag.
- Prompt stress tests: Slight rephrasing that causes large answer changes indicates instability.
Brands already working on LLM authority ranking and semantic optimization AI often detect hallucination patterns earlier because their content produces more consistent answers.
Correction Mechanisms
Once hallucinations are identified, correction must be systematic, not reactive.
Effective correction layers
Source grounding
Ensure AI-accessible pages explicitly state facts in simple, declarative language. Avoid implied or narrative-only claims.
Negative correction statements
Clearly state what is not true. For example, clarifying certifications you do not hold reduces inferred assumptions.
Canonical fact blocks
Repeat key facts consistently across authoritative pages rather than burying them in long-form content.
Prompt-level constraints
When using internal AI tools, enforce rules like: “If unsure, say unknown.”
Structured data alignment
Schema does not just help search it stabilizes factual interpretation. These correction mechanisms work best when aligned with AIO, AEO and GEO strategies, where consistency across formats matters more than volume.
Factual Reinforcement Techniques
Prevention is stronger than correction. Reinforcement ensures AI learns the right facts repeatedly.
High-impact reinforcement techniques
- Entity clarity: One entity, one definition, one source of truth.
- Redundant accuracy (not redundancy): Repeat facts across trusted pages using identical phrasing.
- Evidence proximity: Place proof (certificates, references, citations) immediately after claims.
- Temporal markers: Explicitly state dates like “As of 2026” to reduce outdated hallucinations.
- Comparison boundaries: Define what comparisons are valid and what are not.
From an AI accuracy perspective, reinforcement is not repetition, it is constrained consistency. This is the foundation of anti-hallucination optimization.
Ongoing Monitoring
Hallucination prevention is not a one-time fix. Models update, prompts evolve and new risks emerge.
Ongoing monitoring framework
- Monthly AI audits: Track how major LLMs describe your brand.
- Change detection: Monitor shifts after site updates, rebrands, or mergers.
- Versioned fact logs: Maintain a living document of approved factual statements.
- Feedback loops: Use model feedback tools to flag incorrect outputs when possible.
- Governance ownership: Assign hallucination prevention to a role, not a task.
Brands that integrate hallucination monitoring into broader factual alignment and semantic governance programs consistently see fewer AI errors over time.
FAQs
How do I stop AI from making up info?
You stop hallucinations by grounding AI with clear, repeatable facts, limiting ambiguous prompts and reinforcing verified information across authoritative sources.
Why do LLMs hallucinate even when data exists?
Because models optimize for fluent answers, not strict truth. If facts are unclear, scattered, or implied, the model fills gaps probabilistically.
Can schema markup reduce hallucinations?
Yes. Structured data provides explicit factual anchors that improve consistency across AI-generated responses.
Is hallucination prevention a one-time setup?
No. Ongoing monitoring and reinforcement are required as models, data and brand information evolve.